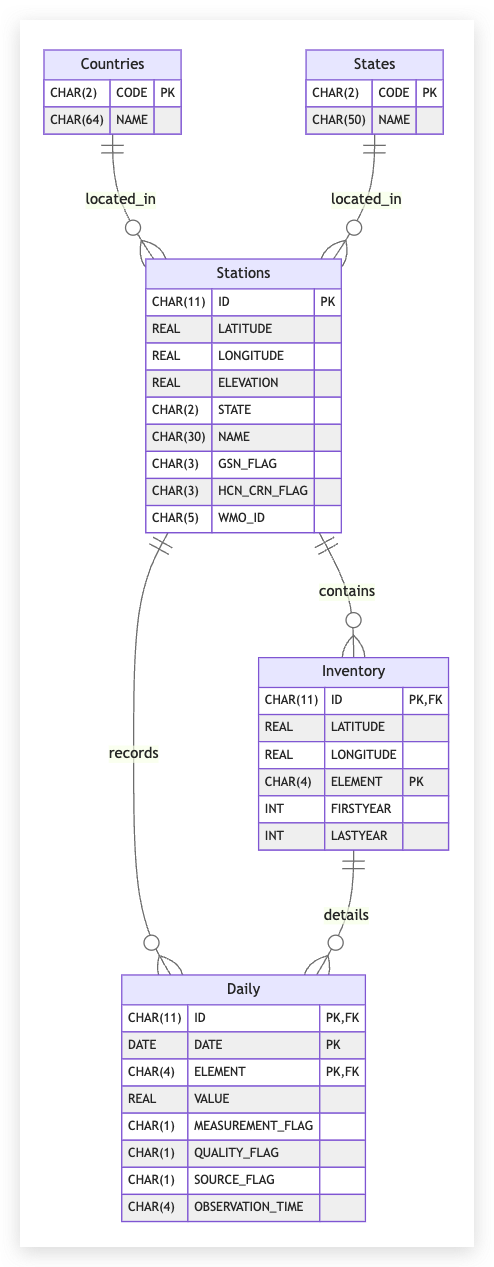
Here is a detailed list of all PySpark APIs and concepts that are either explicitly mentioned or implied in the tasks outlined in the image. This will give you a roadmap of what you need to study in PySpark to tackle the problem efficiently.
1. Reading and Loading Data
spark.read.csv(): For reading CSV files into DataFrames, which would be crucial for loading GHCN daily datasets.spark.read.format(): For reading data from different formats like Parquet, JSON, and others.load(path): For loading datasets from HDFS or other distributed storage systems.
2. Data Exploration and Metadata
DataFrame.show(): To display the first few rows of the dataset.DataFrame.printSchema(): To print the schema of the DataFrame and understand its structure.DataFrame.describe(): For generating summary statistics of the DataFrame.DataFrame.columns: To retrieve the column names.DataFrame.schema: To check the schema definition of the DataFrame.
3. Data Cleaning and Transformation
DataFrame.na.fill(): For filling null or missing values.DataFrame.na.drop(): For dropping rows with null values.DataFrame.withColumn(): For creating or modifying a column in a DataFrame.DataFrame.filter()/DataFrame.where(): For filtering rows based on conditions.DataFrame.selectExpr(): For selecting columns using SQL expressions.DataFrame.distinct(): To remove duplicate rows from a DataFrame.
4. Aggregation and Grouping
DataFrame.groupBy(): For grouping data based on one or more columns.DataFrame.agg(): For performing aggregation operations (e.g., sum, count, average).DataFrame.count(): To count the number of rows in a DataFrame.DataFrame.approxQuantile(): For calculating approximate quantiles for large datasets.
5. Data Joining and Relationships
DataFrame.join(): For joining DataFrames based on common columns or keys.DataFrame.alias(): For aliasing DataFrames when performing self-joins or other joins.DataFrame.union(): To combine two DataFrames.DataFrame.crossJoin(): For performing a cross join between DataFrames.DataFrame.withColumnRenamed(): For renaming columns, which is sometimes needed after joins.
6. Window Functions
Window.partitionBy(): For defining partitions in window functions.Window.orderBy(): For ordering rows within a window.DataFrame.withColumn(): Using window functions for calculations over a rolling window or by partitions.
7. SQL Operations
spark.sql(): To execute SQL queries directly on DataFrames.DataFrame.createOrReplaceTempView(): To create a temporary view to run SQL queries against.DataFrame.sqlContext: To create and use SQLContext for writing SQL-like queries.
8. Advanced Functions
DataFrame.apply(): For applying custom Python functions on columns.pyspark.sql.functions: You will need to import various functions such ascol,lit,expr,when, andconcat, among others, to manipulate data efficiently.pyspark.sql.types: For defining custom data types (e.g.,StructType,ArrayType,MapType, etc.).explode(): For splitting arrays or maps into individual rows.
9. File I/O
DataFrame.write.csv(): For writing data back as CSV files.DataFrame.write.parquet(): For writing data in the Parquet format.DataFrame.write.mode(): For defining write modes such asoverwrite,append, etc.
10. Partitioning and Bucketing
DataFrame.repartition(): For repartitioning DataFrames to optimize performance.DataFrame.coalesce(): For reducing the number of partitions.DataFrame.partitionBy(): To partition the output data based on specific columns when saving.
11. User-Defined Functions (UDFs)
pyspark.sql.functions.udf(): For defining custom UDFs to apply complex functions to columns.pyspark.sql.types: For defining the return type of UDFs (e.g.,StringType,IntegerType).
12. Data Sampling
DataFrame.sample(): To take random samples from a DataFrame.
13. Saving and Persisting Data
DataFrame.persist(): For persisting DataFrames in memory or disk for repeated operations.DataFrame.cache(): For caching the DataFrame to improve performance on repeated operations.DataFrame.unpersist(): For manually unpersisting a DataFrame.
14. Optimization
spark.conf.set(): To set specific configurations (e.g., shuffle partitions, memory settings).- Broadcast Variables: To optimize joins where one DataFrame is significantly smaller than the other (
broadcast(df)).
15. Error Handling and Debugging
DataFrame.explain(): For explaining the execution plan of a DataFrame operation.DataFrame.isEmpty(): To check whether a DataFrame is empty.DataFrame.rdd.getNumPartitions(): For checking the number of partitions in an RDD or DataFrame.
16. Interaction with HDFS
spark.read.text(): For reading raw text data from HDFS.DataFrame.write.mode("overwrite").csv("path"): For writing DataFrames back to HDFS as CSV files.hdfs dfscommands: To interact with the HDFS filesystem (from command-line, not PySpark itself).
17. Running Jobs
spark-submit: Command to submit PySpark jobs to the cluster.sparkContext.parallelize(): For creating RDDs manually when required.
18. Performance Considerations
broadcast(): To handle small datasets more efficiently during joins.DataFrame.checkpoint(): For saving intermediate DataFrames to disk for fault tolerance during long computations.
19. Regression and Statistical Analysis
pyspark.mllibrary: For using machine learning algorithms to handle any advanced analysis (e.g., regression models).pyspark.ml.stat.Correlation.corr(): For calculating correlation between variables.
Recommendations for Study
- Start with DataFrame Basics: Understand the basics of reading, filtering, and transforming data.
- Explore SQL Integration: Get comfortable with writing SQL queries in PySpark and combining DataFrames.
- Aggregation and Grouping: Master groupBy, agg, and window functions for summarizing data.
- Advanced Topics: Dive into UDFs, partitioning, and performance optimization.
- Practice with HDFS: Ensure you understand how to load data from HDFS, work with distributed file systems, and write back results.
- Experiment with
spark-submit: Learn how to submit jobs in a production-like environment.
This comprehensive list should give you a roadmap for tackling your PySpark tasks and getting comfortable with the APIs and techniques you’ll need for this assignment.